编写高速缓存友好代码
开篇
上一篇博文详细介绍了高速缓存的组织结构,并通过实例说详细明了cpu从高速缓存中取数据的过程,对于缓存的工作机制应该有了清晰的认识。这篇博文就来简单讨论以下对于缓存在实际开发中的应用,这里将告诉你如何让你的程序充分利用该缓存,即如何编写高速缓存友好的代码。
用空间换时间
在搞算法的时候经常能听到这种说法,算法研究中通常要考虑算法的时间、空间复杂度。而这里“用空间换时间”说的是通过牺牲一些存储块代码更有效的利用缓存。从而提高程序的运行效率。可见,高效的代码不仅依赖于良好的算法,编写缓存有好代码也很重要。
我们将通过下面的例子来认识这一过程
注:这里假设高速缓存是直接映射的,即每一组只有一行。

通过”局部性“相关的知识,我们可以看出上面的代码有良好的空间局部性:一维向量 x[] 、y[] 都是对其元素进行步长为1的顺序访问。那么,拥有良好局部性的代码,是否就能有效的利用高速缓存呢。不一定。
设上面代码运行在拥有直接映射缓存的计算机上。
为了把问题描述清楚,这里有一些假设
1、float 是4 byte,所以数组x[]占用空间为32byte,y[]也一样
2、x[]存储在内存中地址0-31的位置,y[]紧随其后在地址开始为32的连续位置。(如果觉得牵强你可理解为虚拟地址)
3、直接映射高速缓存有两个组,每组的大小为16byte。也就是高速缓存中每组可存储4个元素。
根据这些假设,每个x[i]、y[i]会被映射到相同的高速缓存组
元素和缓存之间的映射关系如下图所示
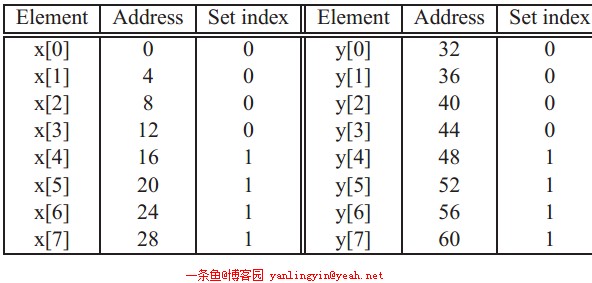
图被中间的双线条分为左右两栏,左边是x[]的情况,右边y[]的情况。
看左边的一栏,左边的一列代表的x 中的元素,中间的是元素在内存中的地址,第三列是该元素映射在缓存中的组号。
为什么会是这样分配的呢,其实在上一篇博文中就有提到。(参看前面的博客会有更好的效果)
这里还是简单的说一下:
主存中的数据是根据地址被映射到缓存的不同位置的,二进制地址的不同位代表不同的信息,一般来说从左到右分别代表:行、组、偏移。
缓存的每一行是16byte,从而可推断缓存的地址位是4 。因为4个二进制的组合共有16种情况(也即2的4次方是16)。
下表是它们地址各个位及代表的信息。
X[]:
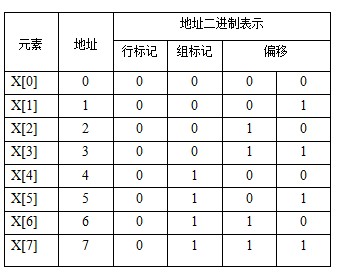
注:这里的地址不是元素的真实地址,指的是块地址。x有八个元素,每个元素占四个byte,我们把这四个byte当作一个整体, 那么x[0]就是第一块,x[1]为第二块,以此类推。y的情况相同。
上图中,阴影部分的为地址的二进制表示形式。每个地址被表示成了四位的二进制数。
其中:
左边一位标记行。因为是直接映射,每组只有一行,所以一位就能表示。
左边第二位标记组。我们讨论的这个缓存只有两个组,一位就能标记。
右边两表示偏移。每行中有四个数据块,所以两位能标识。
可以看出,x[]的前四个元素属于同一组,后四个为另一组。
下面是y[]的情况:
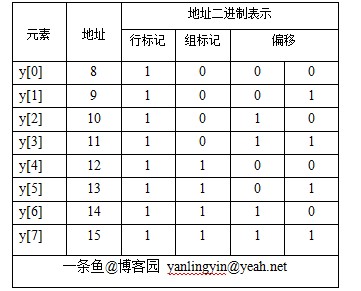
现在对于刚才那个图(如下)应该有更清楚的认识了把。
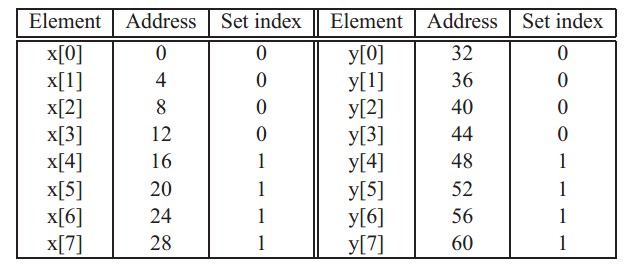
x[i]和y[i]有相同的组标记、不同的行标记,这就意味着x[i]和y[i]不能同时存在于缓存中。
下面模拟一下上述代码的执行过程。我们假设局部变量sum存于cpu寄存器中。